The typical approach to RAG (retrieval augmented generation) is the following
- Chunk your set of documents, transform them into embeddings and index them into a vector database.
- For a given question, transform it into an embedding.
- Find the most similar document chunks to your question by querying the vector store.
- Create a prompt containing the similar documents and the question.
- Submit the prompt to your LLM to answer the question.
This setup seems to work reasonably well, however it is based on some assumptions that are not always true. One assumption being made here is that questions and document chunks exist in the same embedding space therefore comparing a question embedding and a document chunk embedding should provide a good measure of their similarity. This is not always true. For example in the case of RepoGPT, questions are written in natural language but document chunks mostly contain code. Another assumption is that the information that the LLM needs to answer a question is contained in the document chunks that are most similar to the question. This is also not always true. There are certainly cases where the document chunk required to answer the question is not at all similar to the question itself. Conversely, there are many cases where document chunks that are similar to the question are not required to answer the question.
One way to mitigate the issues caused by these assumptions is to use more of a semi-supervised learning approach. One thing to consider is that LLMs do not only need to be used for answering the given question, they can also be used to decide whether a given document chunk is relevant for answering the given question. For example, one could create a prompt that contains the document chunks returned by the vector store and the given question and ask the LLM to return a json response indicating which of the document chunks are relevant to answering the question and which are not. Now you have not only the question but also a set of chunks that the LLM knows are relevant to answering the question. What now? What if you queried the vector store again but this time you query it with the question and the relevant documents? Now what is returned by the vector store are document chunks that are similar to relevant document chunks (not just the question). Then repeat the process until the number of relevant document chunks stops increasing. Below is a diagram of this process.
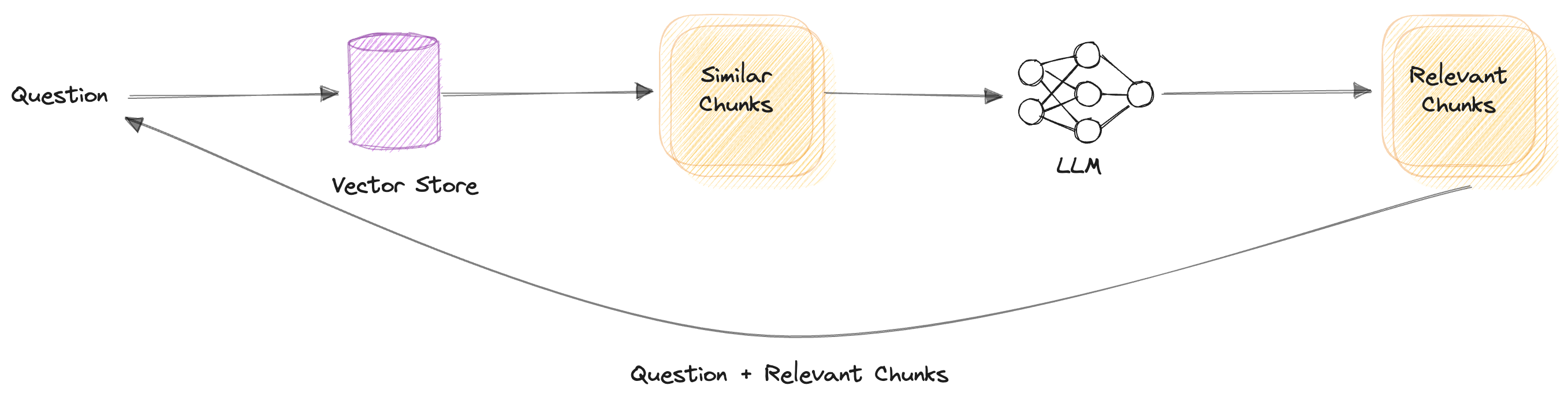
This approach mitigates the embedding space problem because now the queries to the vector store actually contain document chunks from the vector store. Therefore, the queries vectors will now be in the same vector space as the document chunk vectors. Also, it mitigates the query similarity problem because now we are not only incorporating document chunks that are similar to the query but also similar to document chunks that we know are relevant to answering the given question.
Example
Let’s use a case from RepoGPT as an example. Take the question show the full seed method in the ElkanKMeansPlusPlusClusterer class containing all the lines in the method
applied to the Java-based Apache Commons Math library repo. The reponse from
RepoGPT was
The seed method does not seem to be fully available in the provided snippets. We can only see the beginning parts of the seed method, particularly starting definition and first few lines in the method body from the snippet 0. To get the rest lines in the method we need more information.
Nevertheless, from the available snippets, this is how the seed method in the `ElkanKMeansPlusPlusClusterer` class looks like:
'''java
private double[][] seed(final List<T> points) {
final int k = getNumberOfClusters();
final UniformRandomProvider random = getRandomGenerator();
final double[][] result = new double[k][];
final int n = points.size();
final int pointIndex = random.nextInt(n);
final double[] minDistances = new double[n];
int idx = 0;
result[idx] = points.get(pointIndex).getPoint();
double sumSqDist = 0;
//...
// The method continues but the rest of the lines are not in the provided snippets.
'''
As you can see the method is getting cut off and the reason for this is that the full method was not provided in the similar documents returned by the vector store. Specifically, the relevant chunk returned was cut off as shown below.
/**
* kmeans++ seeding which provides guarantee of resulting with log(k) approximation
* for final clustering results
* <p>
* Arthur, David, and Sergei Vassilvitskii. "k-means++: The advantages of careful seeding."
* Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms.
* Society for Industrial and Applied Mathematics, 2007.
*
* @param points input data points
* @return an array of initial clusters centers
*
*/
private double[][] seed(final List<T> points) {
final int k = getNumberOfClusters();
final UniformRandomProvider random = getRandomGenerator();
final double[][] result = new double[k][];
final int n = points.size();
final int pointIndex = random.nextInt(n);
final double[] minDistances = new double[n];
int idx = 0;
result[idx] = points.get(pointIndex).getPoint();
double sumSqDist = 0;
and the subsequent chunk continuing the method was not returned by the vector store because it was not similar enough to the given question (but obviously still relevant).
Now let’s try the semi-supervised retrieval approach outlined earlier. The first step is to ask the LLM which of the similiar code chunks is relevant to answering the given question. You could use a prompt like
You will be given a json string where the keys are indexes and the values are snippets of code from a repo with some
contextual information above them. You will also be given a question to answer based on these snippets. The snippets of
code were generated by finding the snippets from the repo with the highest semantic similarity to the question string.
Therefore even though these snippets are semantically similar to the question string, they may or may not be useful for
answering the question. Your job is to decide which snippets are useful for answering the question and which are not
useful. Return a json string where the keys are the snippet indexes and values are true or false based on whether that
snippet is useful for answering the given question string. The json string containing the code snippets is
{similar_chunks} and the question string is: {question_str}.
The LLM’s reponse is
{"0": true, "1": false, "2": false, "3": false, "4": false, "5": false, "6": false, "7": false, "8": false, "9": false, "10": false, "11": false, "12": false, "13": false, "14": false, "15": false, "16": false, "17": false, "18": false, "19": false}
which indicates that the first chunk retrieved (the one shown) was deemed relevant by the LLM and the rest were not.
The next step is to take that first chunk that was deemed relevant and combine it with the question and use that to query the vector store. Then repeat the previous step that evaluates the relevance of the returned documents. The result is
{"0": true, "1": true, "2": false, "3": false, "4": false, "5": false, "6": false, "7": false, "8": false, "9": false, "10": false, "11": false, "12": false, "13": false, "14": false, "15": false, "16": false, "17": false, "18": false, "19": false}
As you can see now we have 2 relevant document chunks. As you may have guessed, the new relevant document chunk corresponds to the chunk of the method we were missing i.e.
for (int i = 0; i < n; i++) {
final double d = distance(result[idx], points.get(i).getPoint());
minDistances[i] = d * d;
sumSqDist += minDistances[i];
}
while (++idx < k) {
final double p = sumSqDist * random.nextDouble();
int next = 0;
for (double cdf = 0; cdf < p; next++) {
cdf += minDistances[next];
}
result[idx] = points.get(next - 1).getPoint();
for (int i = 0; i < n; i++) {
final double d = distance(result[idx], points.get(i).getPoint());
sumSqDist -= minDistances[i];
minDistances[i] = Math.min(minDistances[i], d * d);
sumSqDist += minDistances[i];
}
}
return result;
}
This makes sense since our new query contained a chunk that was very semantically similar to it.
The final step is to pass the two relevant chunks and the given question to the LLM and actually ask it to answer the question this time. The result is
The full `seed` method in the `ElkanKMeansPlusPlusClusterer` class including all the lines in the method looks like this:
'''java
/**
* kmeans++ seeding which provides guarantee of resulting with log(k) approximation
* for final clustering results
* <p>
* Arthur, David, and Sergei Vassilvitskii. "k-means++: The advantages of careful seeding."
* Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms.
* Society for Industrial and Applied Mathematics, 2007.
*
* @param points input data points
* @return an array of initial clusters centers
*
*/
private double[][] seed(final List<T> points) {
final int k = getNumberOfClusters();
final UniformRandomProvider random = getRandomGenerator();
final double[][] result = new double[k][];
final int n = points.size();
final int pointIndex = random.nextInt(n);
final double[] minDistances = new double[n];
int idx = 0;
result[idx] = points.get(pointIndex).getPoint();
double sumSqDist = 0;
for (int i = 0; i < n; i++) {
final double d = distance(result[idx], points.get(i).getPoint());
minDistances[i] = d * d;
sumSqDist += minDistances[i];
}
while (++idx < k) {
final double p = sumSqDist * random.nextDouble();
int next = 0;
for (double cdf = 0; cdf < p; next++) {
cdf += minDistances[next];
}
result[idx] = points.get(next - 1).getPoint();
for (int i = 0; i < n; i++) {
final double d = distance(result[idx], points.get(i).getPoint());
sumSqDist -= minDistances[i];
minDistances[i] = Math.min(minDistances[i], d * d);
sumSqDist += minDistances[i];
}
}
return result;
}
'''
which is now the correct answer.
Conclusion
In this post a semi-supervised retrieval approach has been presented that seems to mitigate some of the negative effects of embedding-based vector search in RAG. Of course there are some disadvantages to this approach as well - this approach would require an increased number of LLM API calls which would increase latency and cost however this may be a reasonable tradeoff for some applications.